选取模型为SenseVoiceSmall .
开始运行前首先需要将模型转换为 OpenVINO IR 格式. 原模型为 PyTorch 框架, 可以利用以下代码保存为 ONNX 格式.
onnx_model = onnx.load(model_path) onnx.save_model(onnx_model, 'saved_model.onnx' , save_as_external_data=True , all_tensors_to_one_file=True , location='data/weights_data' , size_threshold=1024 , convert_attribute=False )
也可以直接下载 FunASR 官方提供的SenseVoiceSmall-onnx 模型. 准备好 ONNX 格式模型后, 可以利用 OpenVINO 提供的mo或ovc工具将其转换为 OpenVINO IR 格式. 在最新的 OpenVINO 版本中, mo工具已经被更简化的OpenVINO Model Converter即ovc工具所替代.
mo --input_model <INPUT_MODEL>.onnx
此命令会将模型优化并导出为 OpenVINO IR 格式模型. 注意, --compress_to_fp16默认处于开启状态, 会将模型压缩至 fp16 精度, 正常情况下不会导致明显的精度损失.
可以通过如下代码加载并编译 OpenVINO IR 模型.
import openvino as ovmodel_path = r"/saved_model.xml" model = ov.compile_model(model_path, "AUTO" )
需要注意的是, 原模型采用 FunASR 提供的AutoModel类加载并调用, 而在转换为 OpenVINO 后由于模型类改变, 无法用原方法调用. 因此, 需要将原模型调用过程中, 对音频进行前处理后的数据导出, 用编译后的模型运算, 再将模型输出手动解码输出.
原模型的调用方法如下.
from funasr import AutoModelfrom funasr.utils.postprocess_utils import rich_transcription_postprocessmodel = AutoModel( model=model_dir, trust_remote_code=True , device="gpu" , disable_update=True , ) res = model.generate( input ="./vad_example.wav" , cache={}, language="auto" , use_itn=True , batch_size_s=60 , vad=False , ) text = rich_transcription_postprocess(res[0 ]["text" ]) print (text)
为导出前处理后数据, 需要给原模型的encoder添加 hook, 代码如下.
hook_layer = model.model.encoder.encoders0[0 ] all_feats = [] def save_feats_hook (module, input , output ): feats = input [0 ] feats_np = feats.detach().cpu().numpy() all_feats.append(feats_np) print ("已保存中间特征: " , feats.shape) hook_handle = hook_layer.register_forward_hook(save_feats_hook) res = model.generate( input ="./vad_example.wav" , cache={}, language="auto" , use_itn=True , batch_size_s=60 , vad=False , ) all_feats = np.concatenate(all_feats, axis=1 ) np.save("example_feats.npy" , all_feats) np.save("example_feats_len.npy" , np.array([all_feats.shape[1 ]], dtype=np.int32)) hook_handle.remove()
注意, 如果在导出前处理数据时开启 vad, 会导致按乱序导出数据, 识别内容虽然正确, 但对稍长的文本, 每句话之间的顺序会出现错乱, 故不应开启 vad.
调用编译后模型代码如下.
import numpy as npspeech = np.load("example_feats.npy" ) speech_lengths = np.load("example_feats_len.npy" ) print (f"Speech shape: {speech.shape} , Lengths: {speech_lengths} " )language = np.array([0 ], dtype=np.int32) textnorm = np.array([1 ], dtype=np.int32) inputs = { "speech" : speech, "speech_lengths" : speech_lengths, "language" : language, "textnorm" : textnorm, } results = model(inputs)
此时results内保存内容为识别文字对应 token, 需手动解码并输出. 为此, 首先需要找到原模型的tokens.json文件, 并编写解码函数如下, 其中rich_transcription_postprocess是 FunASR 提供的用于将情感标识, 语言标识等符号转换为可读形式的函数.
import jsonwith open (r".\SenseVoiceSmall-onnx\tokens.json" , "r" , encoding="utf-8" ) as f: token_list = json.load(f) blank_id = token_list.index("<unk>" ) logits = results["ctc_logits" ] logits = np.squeeze(logits, axis=0 ) token_ids = np.argmax(logits, axis=-1 ) def decode (ids, blank=0 ): output = [] prev = blank for i in ids: if i!= prev and i != blank: output.append(i) prev = i return output decoded_ids = decode(token_ids, blank=blank_id) text = "" .join(token_list[i] for i in decoded_ids) text = rich_transcription_postprocess(text) print (text)
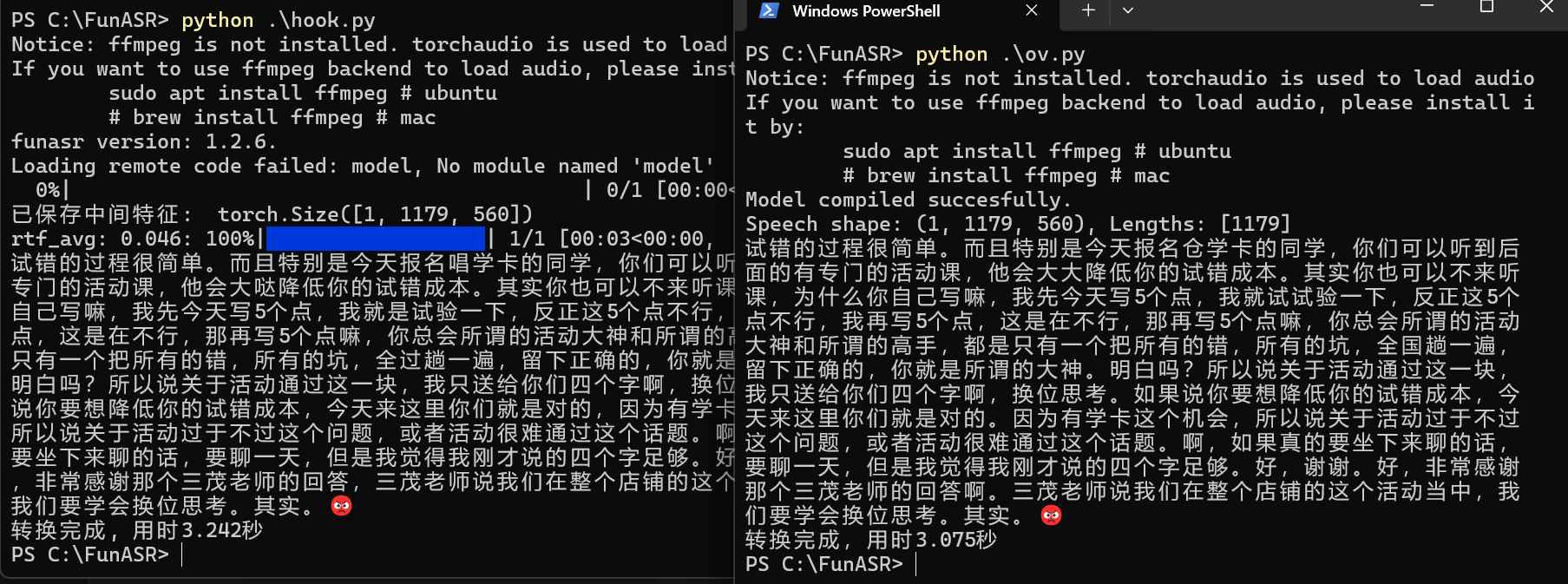
即可完成利用 OpenVINO 的模型调用, 效果如图.
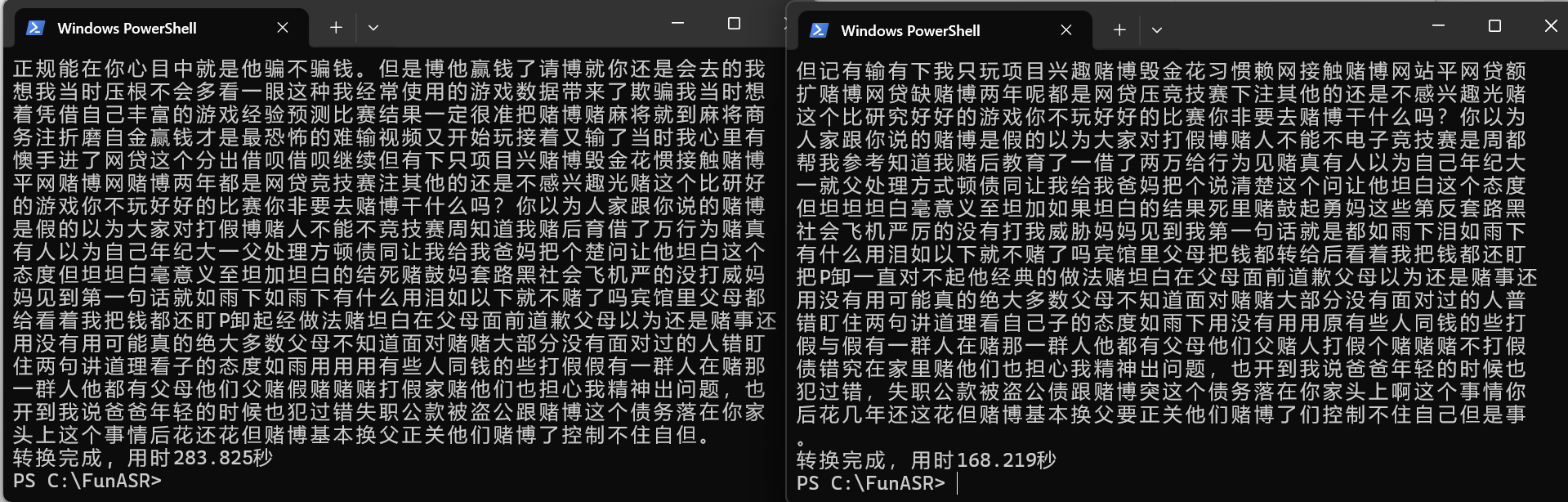
img 实验表明, 在音频不长 (约 1 分钟) 时, 是否使用 OpenVINO 对模型效率影响不大, 但在音频文件略长 (约 13 分钟) 时, 使用 OpenVINO 会显著提升模型效率, 如图.
img 如果尝试在 NPU 上运行模型会导致报错, 错误信息如下.
Traceback (most recent call last): File "C:\FunASR\ov.py", line 15, in <module> model = ov.compile_model(model_path, "NPU") File "C:\Users\MTL659\AppData\Local\Programs\Python\Python310\lib\site-packages\openvino\runtime\ie_api.py", line 631, in compile_model return core.compile_model(model, device_name, {} if config is None else config) File "C:\Users\MTL659\AppData\Local\Programs\Python\Python310\lib\site-packages\openvino\runtime\ie_api.py", line 543, in compile_model super().compile_model(model, device_name, {} if config is None else config), RuntimeError: Exception from src\inference\src\cpp\core.cpp:124: Exception from src\inference\src\dev\plugin.cpp:58: Exception from src\plugins\intel_npu\src\plugin\src\plugin.cpp:717: Exception from src\plugins\intel_npu\src\compiler_adapter\src\ze_graph_ext_wrappers.cpp:389: L0 pfnCreate2 result: ZE_RESULT_ERROR_INVALID_ARGUMENT, code 0x78000004 - generic error code for invalid arguments . [NPU_VCL] Compiler returned msg: Upper bounds were not specified, got the default value - '9223372036854775807'
推测是 NPU 不支持动态input shape导致, 可能需要进一步研究.