数据库复习笔记 五.数据库的保护
数据库的安全性#
用户标识和鉴别#
CREATE USER <username> IDENTIFIED BY <password> |
存取权限控制#
- 数据对象
- 操作类型
对谁, 干什么.
GRANT SELECT(操作类型) ON Student(数据对象) TO User1; |
操作类型: SELECT, INSERT, DELETE, UPDATE, ALTER, INDEX, ALL
收回权限:
REVOKE [CONNECT | RESOURCE | DBA] FROM <username> |
数据对象的粒度: 粒度越细, 灵活性/安全性越高, 但开销越大.
粗粒度: 例如给你整个表的访问权限; 细粒度: 例如只给你表中某一列的权限.
列级控制: SQL 原生支持.
GRANT SELECT(name, age) ON Student TO User1 |
行级控制一般通过视图实现:
CREATE VIEW Boys AS SELECT * FROM Student WHERE Sex='男'; |
使用视图#
可以通过建立视图屏蔽用户不该看到的数据内容, 但视图的主要功能是实现数据独立性, 其安全保护功能不够精细.
数据加密#
审计#
记录对数据库的访问存取痕迹.
分为用户级和系统级:
- 用户级主要是由用户设置, 针对用户自己创建的对象的审计, 包括对这些对象的各种访问
- 系统级审计是 DBA 进行的, 针对用户登录的成功与否以及对数据库级权限的操作
消耗大量时间和空间资源, 所以一般作为可选项可灵活打开和关闭.
例:
对 SC 表的 ALTER 和 UPDATE 进行审计:
AUDIT ALTER, UPDATE ON SC |
取消对 SC 表的任何审计:
NOAUDIT ALL ON SC |
数据库的完整性#
数据库安全性是防止非法用户的非法操作, 而完整性是是防止不合语义的数据, 例如防止出现负数年龄.
加在数据库数据之上的语义约束条件称为数据库完整性约束条件, DBMS 中检查数据是否满足完整性条件的机制称为完整性检查.
完整性约束条件作用的对象可以分为: 列级, 元组级和关系级三个粒度.
- 列级约束: 列的取值类型, 范围, 精度排序等
- 元组级约束: 记录中各个字段之间的联系
- 关系级约束: 多个记录或关系之间的联系
完整性约束就其状态可以分为静态和动态的.
- 静态: 反映数据库的状态是合理的
- 动态: 反映数据库的状态变迁是否合理
完整性控制#
- 定义功能: 定义约束条件
- 检查功能: 检查用户的操作请求是否违背了完整性约束条件
- 执行动作: 在发现用户的操作违背了完整性约束条件后, 能采取一定的动作来保证数据的完整性
分为:
- 立即执行:每执行一条 SQL 语句就检查
- 延迟执行: 完成了一套复杂的动作 (事务) 再检查
完整性规则的形式化表示#
(D, O, A, C, P)
Data 数据对象, 例如「工资」属性.
Operation 触发操作, 例如进行 INSERT 和 UPDATE 时检查.
Condition 条件, 例如我们只检查教授的工资.
Assertion 断言/约束, 例如工资必须 >= 1000.
Procedure 违约处理, 例如违规就拒绝执行, 你想违规就报警也可以.
参照完整性应考虑的问题#
- 外键能否为空值: 看情况.
- 父表 (被参照表) 发生变化/删除时怎么办:
- 级联: 诛九族, 改父亲就把孩子也改了, 删父亲就把孩子也鲨了
- 受限: 还有孩子就不许改/删
- 置空: 把孩子的相应外键置为 NULL
数据库的并发控制#
事务#
- 原子性: 不可分割, 要么干完要么不干.
- 一致性: 事务的执行将保持数据库的一致性, 即数据不会因事务的执行而被破坏.
- 隔离性: 并发执行的事务之间不会互相干扰, 最终结果应该和这些事务先后单独执行的结果相同.
- 持久性: 一个事务一旦完成提交, 它对数据库的更新将永久反映在数据库中, 不会因为系统的故障而丢失.
数据库的并发操作导致的问题#
修改丢失#
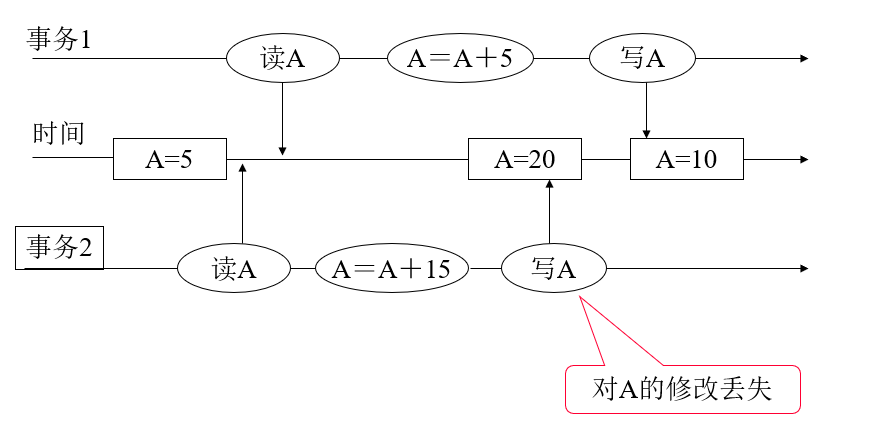
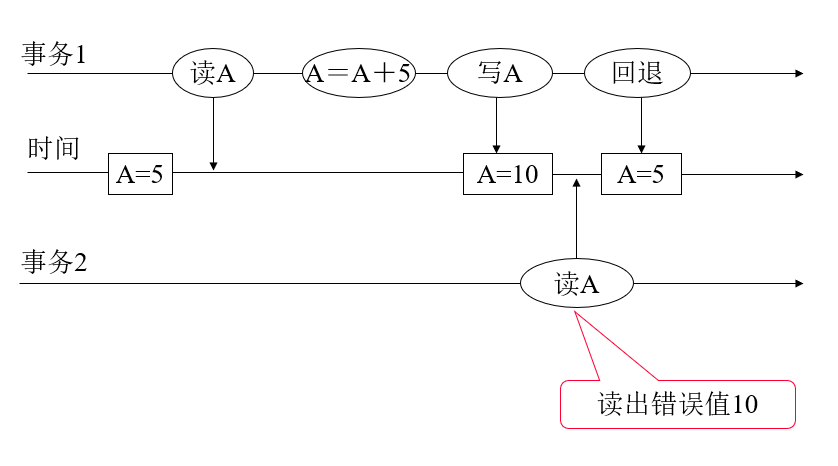
污读问题#
读到脏数据, 正确值应该是读到 A = 5.
现已推出周边污读娃娃, 欢迎大家购买!
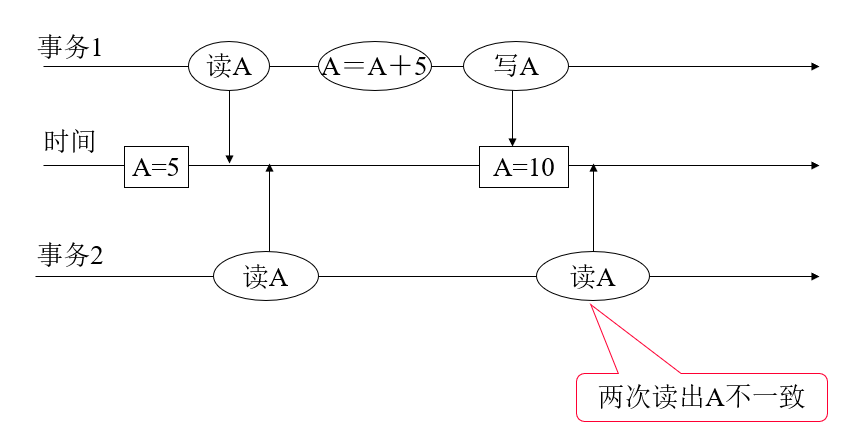
不可重复读问题#
两次读到的 A 不一致.
幻影读问题#
同样的操作返回不同结果.
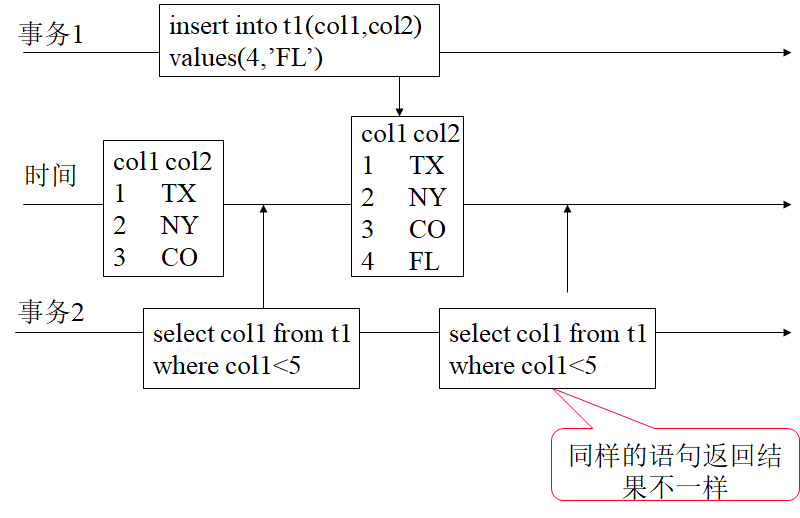
幻影读和不可重复读的区别: 不可重复读是由于别人 UPDATE 了数据, 导致读到的内容发生了变化; 幻影读是由于别人 INSERT 或 DELETE 了数据, 导致读到的行数发生了变化.
可串行性#
并发调度的唯一标准可串行性: 不管怎么乱序执行, 只要最后的结果和轮流执行 (即串行) 相同, 那就是对的.
串行顺序可能有多种 (A -> B 或 B -> A), 只要并发结果等于其中任意一种串行结果, 就算正确.
数据库的封锁机制#
- 排它锁: eXclusive, X 锁, 独占锁, 修改数据时对 A 加 X 锁, 其它事务不能再读写 A, 也不能对 A 加任何类型的锁.
- 共享锁: Share, S 锁, 别的事务能读, 但不能修改, 可以再加 S 锁, 但不能加 X 锁.
- 修改锁: Update, U 锁, 预备马上要更改时加 U 锁, 允许其他人读, 但不允许其他人加 U 锁或 X 锁, 等真正修改时, U 锁升级成 X 锁. 不是所有 DBMS 都有 U 锁.
| 当前锁 / 请求锁 | X 锁 (排它) | S 锁 (共享) |
|---|---|---|
| 无锁 | ✅ 可以 | ✅ 可以 |
| 有 X 锁 | ❌ 冲突 | ❌ 冲突 |
| 有 S 锁 | ❌ 冲突 | ✅ 相容 |
锁的粒度: 粗粒度锁整个数据库/表, 细粒度锁某一行或某一页.
封锁力度大则开销小, 并发度低; 封锁力度小则开销大, 并发度高.
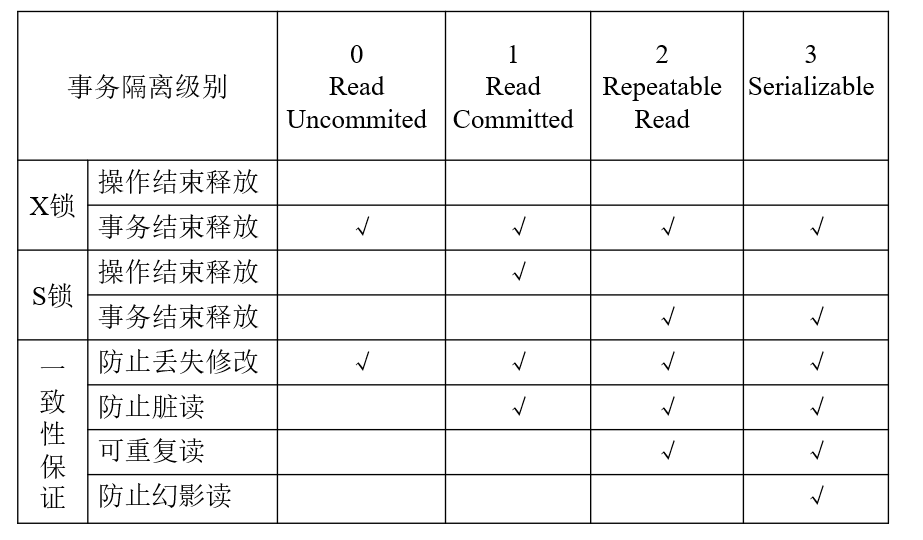
事务隔离级别#
事务隔离级别 0 (READ UNCOMMITTED): 即一级封锁协议
- 事务 T 在修改数据前必须先对其加 X 锁, 直到事务结束才释放. 事务结束可以是正常结束 (Commit) 或非正常结束 (Rollback).
- 事务 T 读数据不加锁.
- 本事务级别防止了修改丢失问题.
- 不能防止脏读和保证重复读.
事务隔离级别 1 (READ COMMITTED): 即二级封锁协议
- 事务 T 在修改数据前必须先对其加 X 锁, 直到事务结束才释放.
- 事务 T 读数据前必须先对其加 S 锁, 读完后即释放 S 锁, 而不是到事务结束才释放.
- 防止了脏读问题.
- 不能保证重复读.
事务隔离级别 2 (REPEATABLE READ): 即二级封锁协议
- 事务 T 在修改数据前必须先对其加 X 锁, 直到事务结束才释放.
- 事务 T 读数据前必须先对其加 S 锁, 直到事务结束才释放.
- 保证重复读.
事务隔离级别 3 (SEARIALIZABLE): 即两阶段封锁协议, 可串行性封锁协议
- 事务中, 在对任何数据读写前首先要获得对数据的锁, 称扩展阶段 (锁的粒度与事务隔离级别 2 有区别).
- 在释放一个锁以后, 不再申请任何锁, 称收缩阶段
- 保证事务可串化执行.
活锁#
由于系统并不是按照事务申请锁的先后来决定哪个事务获得资源锁, 从而导致某个事务可能永远等下去的情况称活锁, 也叫饥饿.
避免活锁的办法: 对锁资源的分配采用先申请先服务的策略.
死锁#
事务 T1 封锁了 A, 事务 T2 封锁了 B, 然后事务 T1 申请封锁 B, 而事务 2 申请封锁 A, 这种 T1 等待 T2 而 T2 又等待 T1 释放资源的情况称死锁.
死锁避免的方法:
- 一次封锁法: 一次将所有用到的数据全部加锁.
- 顺序封锁法: 尽量按照同一次序去访问数据资源.
数据库的恢复#
使发生故障的数据库恢复到一致性状态.
故障种类#
- 事务故障: 逻辑错误, 除以零等, 需要强制回滚 UNDO.
- 系统故障: 系统崩溃, 外设上的数据正常, 内存中的数据全部丢失, 需要 REDO.
- 介质故障: 硬盘爆炸了, 需要装入数爆炸前某个时刻的数据库副本, 并重做自此时刻开始的所有成功事务, 直到发生故障前一时刻.
数据转储#
说人话就是备份.
-
静态转储: 转储时数据库必须无运行的事务, 会影响数据库的生产.
-
动态转储: 转储和事务可以并发运行, 减少对生产的影响, 但转储数据库副本的同时必须记录转储期间的事务, 即事务日志文件, 这样才可以用该后数据库副本和日志文件进行数据库恢复.
-
海量转储 (完全转储): 完全备份所有数据.
-
增量转储: 每次备份在前一次基础上增加的数据.
-
差值转储: 每次备份自上次完全转储以来数据库增加的数据.
日志文件#
用来记录事务对数据库的更新操作的文件.
恢复策略#
- 事务故障: 反向扫描日志文件, 查找该事务更新操作, 对该事务的更新操作执行逆操作 (UNDO) .
- 系统故障: UNDO, 然后正向扫描日志文件, 对重做队列中的事务进行重做 (REDO) .
- 介质故障: 装入最新副本和日志文件, 重做相关事务.
数据库的复制与镜像#
- 对等复制: 各个结点平等, 可以互相复制数据.
- 主从复制: 数据只会从主数据库复制到从数据库.
- 级联复制: 数据从主数据库复制到从数据库后, 再从从数据库复制到其他数据库.